Abstract
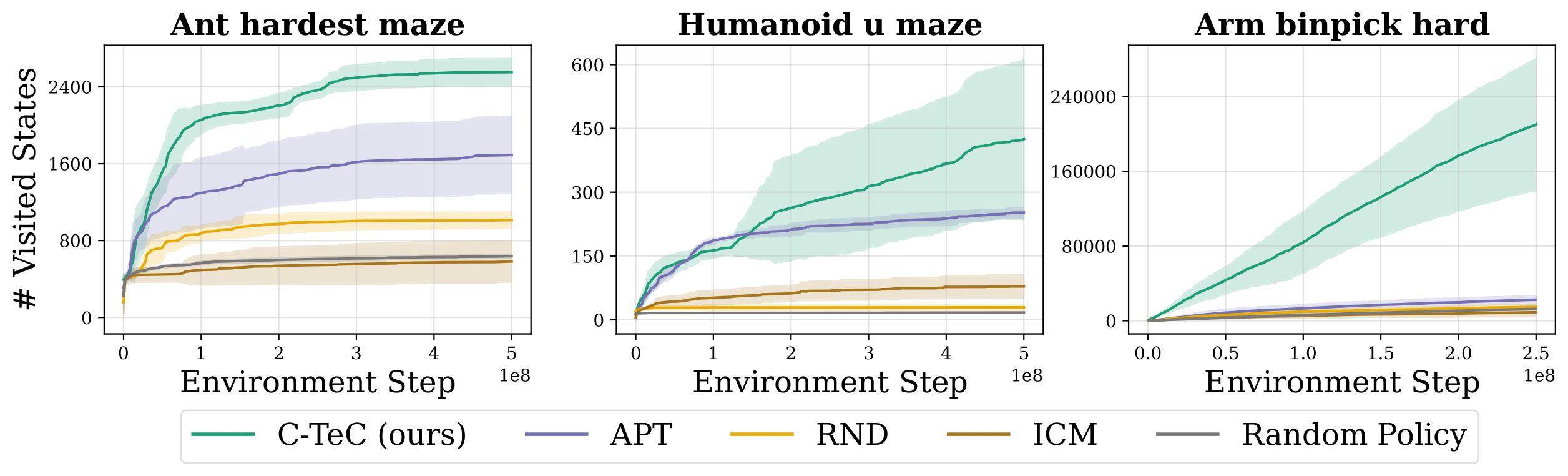
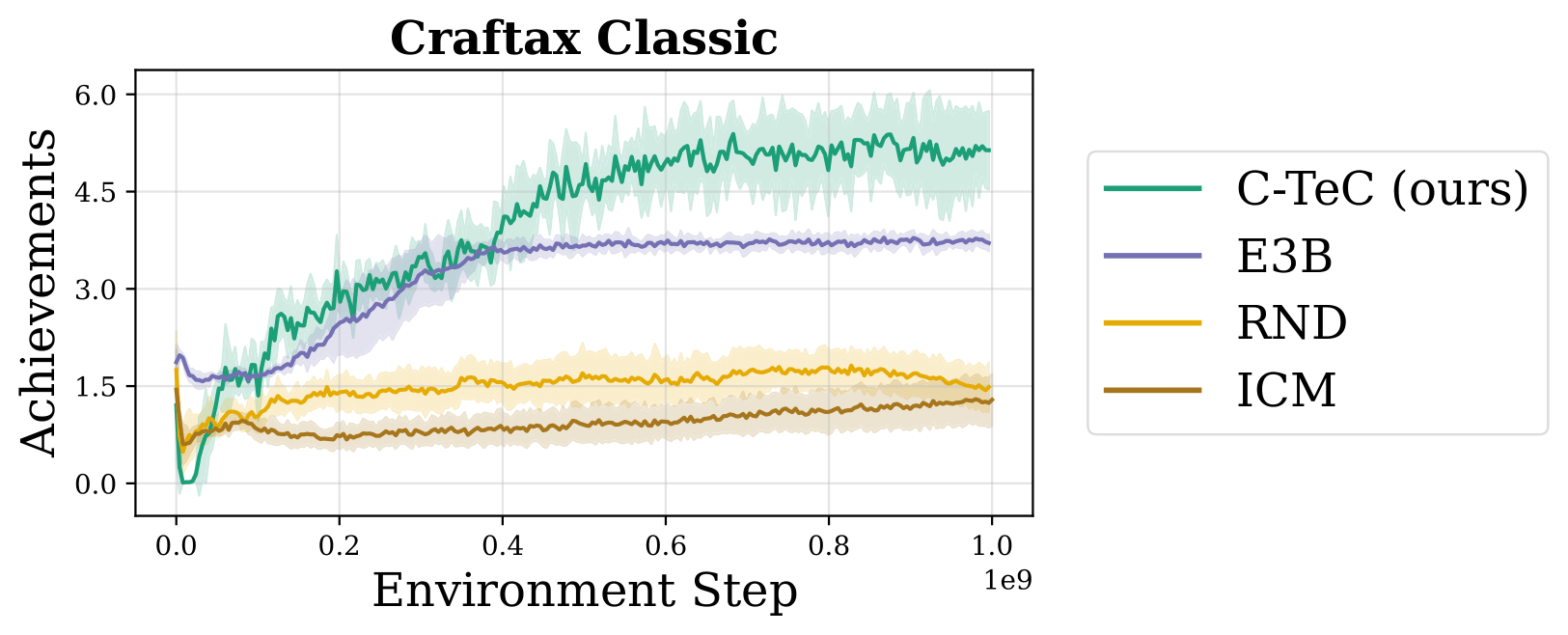
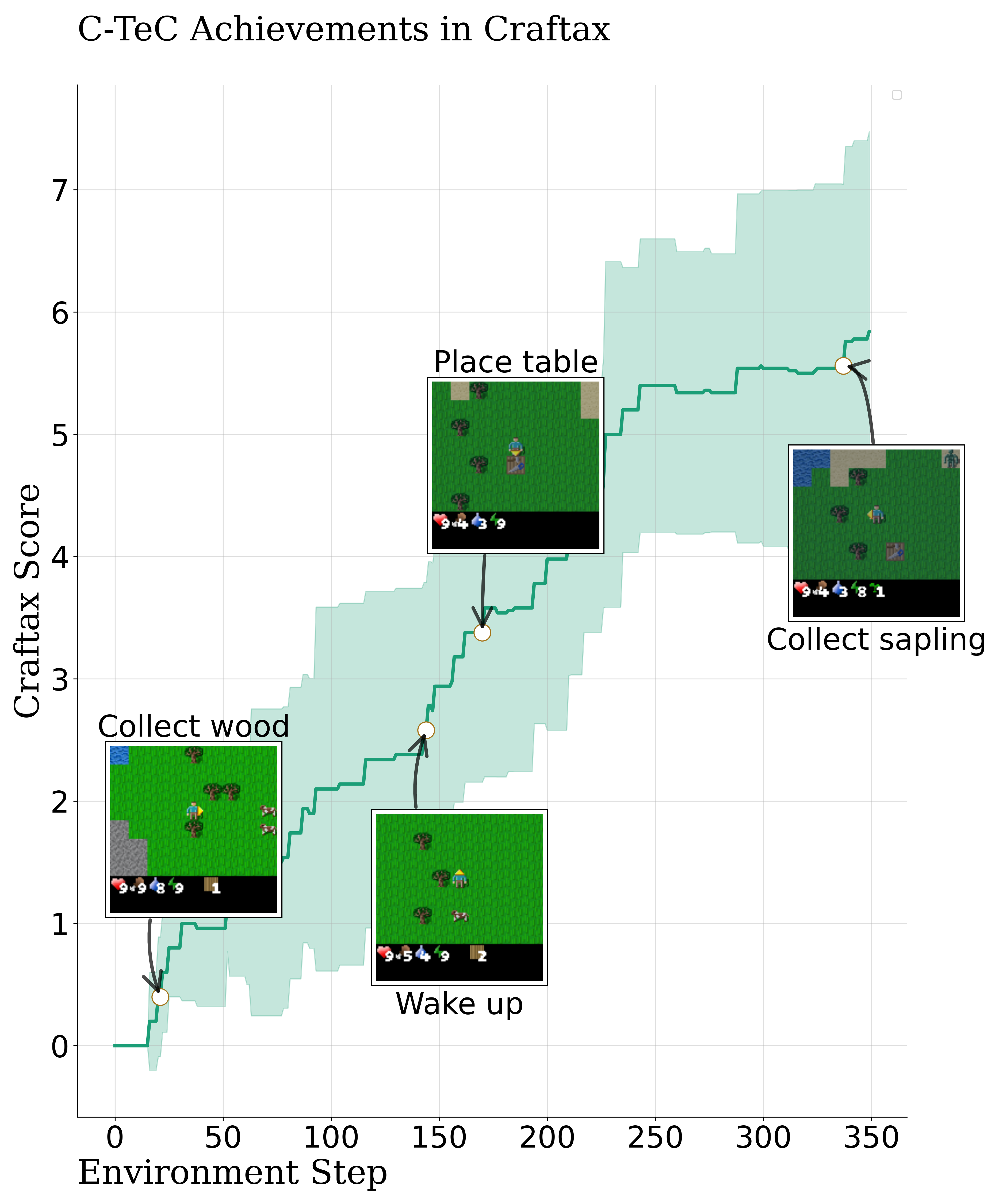
Abstract Effective exploration in reinforcement learning requires not only tracking where an agent has been, but also understanding how the agent perceives and represents the world. To learn powerful representations, an agent should actively explore states that facilitate a richer understanding of its environment. Temporal representations can capture the information necessary to solve a wide range of potential tasks while avoiding the computational cost associated with full-state reconstruction. In this paper, we propose an exploration method that leverages temporal contrastive representations to guide exploration, aiming to maximize state coverage as perceived through the lens of these learned representations. Temporal contrastive representations have shown promising results in goal-conditioned reinforcement learning, unsupervised skill discovery, and empowerment-based learning. We demonstrate that such representations can enable the learning of complex exploratory behaviors in locomotion, manipulation, and embodied-AI tasks, revealing previously inaccessible capabilities and behaviors that traditionally required extrinsic rewards.
Overview
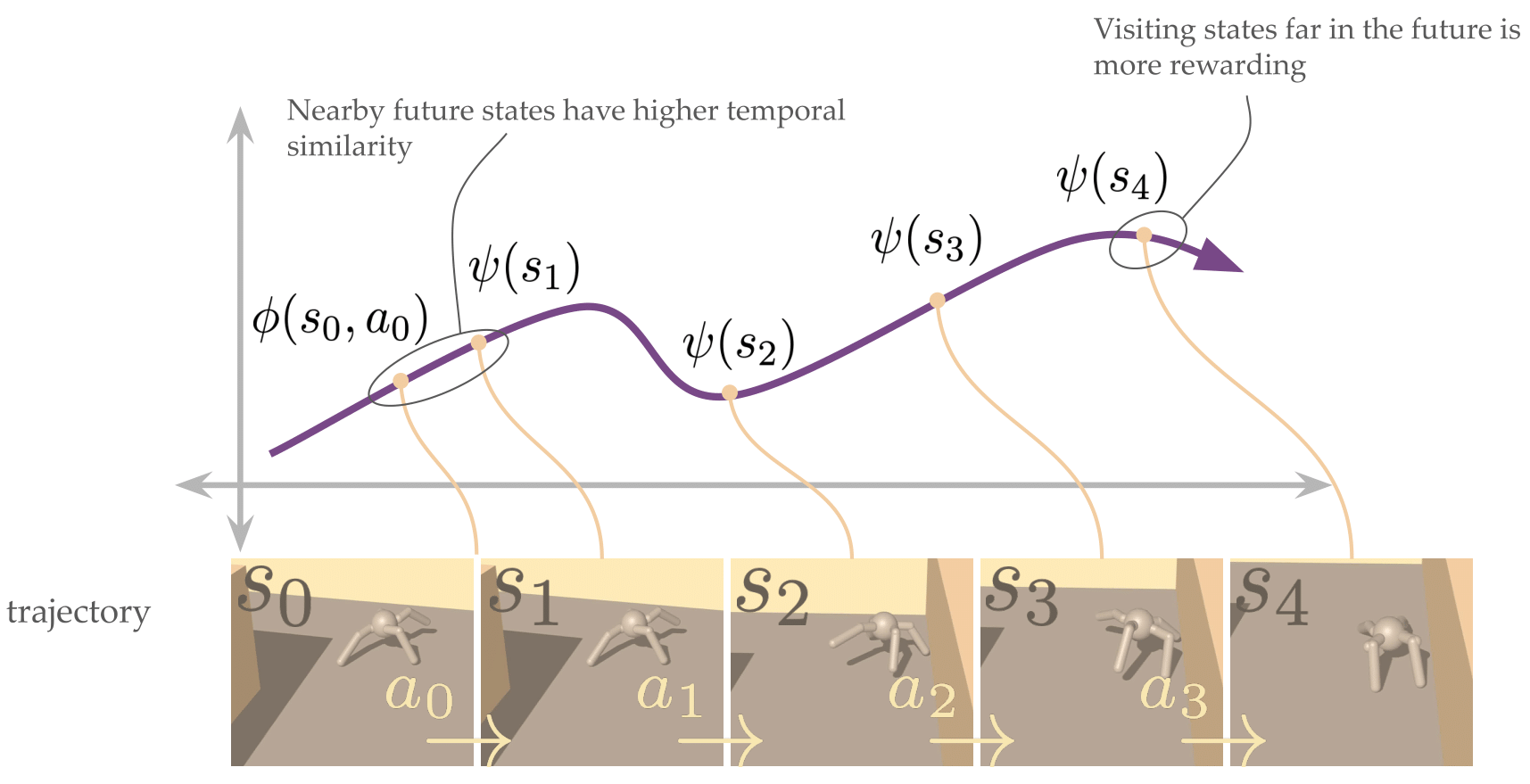
The agent's starting state is $( s_0 )$. We train a contrastive model such that the temporal similarity between the representation of $((s_0, a_0))$ and $( s_{2,3,4,\ldots})$ is high, and we reward the agent for visiting states that are further in the future. For example, the reward for visiting $( s_4 )$ from $( s_0 )$ should be larger than the reward for visiting $( s_3 )$ from the same $( s_0 )$.
Reward Visualization
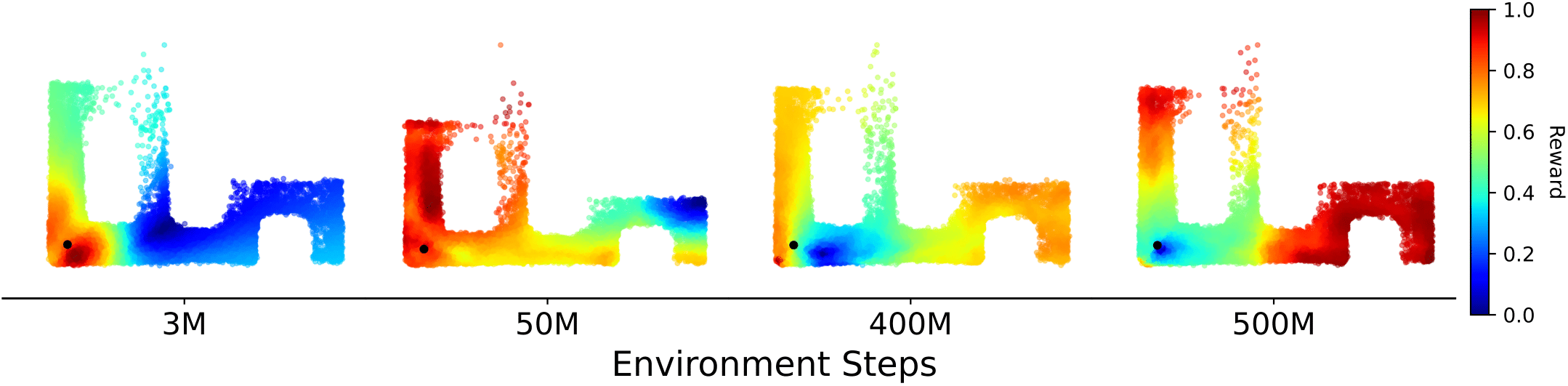
Evolution of the C-TeC reward during training. This figure shows how the intrinsic reward changes over the course of training based on future state visitation. The black circle in the lower-left corner represents the starting state. Early in training (3M steps), higher rewards are assigned to nearby states. As training progresses, the agent explores farther, and the reward increases for more distant regions. All reward values are normalized for visualization.